Анализ данных с целью поддержки принятия решений (IBM DB2 Business Intelligence)
Программные средства, объединяемые названием IBM DB2 Business Intelligence (<деловой интеллект>), предназначены для анализа накопленных (исторических) данных с целью поддержки принятия решений. В настоящее время это направление является одним из наиболее приоритетных в сфере технологий управления данными. Это связано, с одной стороны, с тем, что использование исторических данных может помочь (и помогает) в поиске наилучших решений в деловой деятельности, а, с другой стороны, с возможностями организовать хранение, быстрый поиск необходимых данных и извлечение из них нужной информации (знаний) с помощью современных компьютерных средств.
Функционально программные средства этого направления делят на четыре группы:
- средства анализа данных в реальном масштабе времени (OLAP-On-line Analytical Processing);
- средства cоздания хранилищ данных (Data Warehouse);
- средства поддержки доступа к данным;
- средства интеллектуальной обработки данных, или <добычи информации> (Intelligent Miner).
Анализ данных в реальном масштабе времени (OLAP) осуществляется c целью поддержки принятия решений (оперативных или стратегических) по управлению бизнесом. Информационные системы, поддерживающие этот вид деятельности, называют Системами поддержки принятия решений (СППР).
Термин OLAP был предложен в1993 году Эдвардом Коддом (Э. Кодд - автор реляционной модели данных). По Кодду, OLAP - это технология комплексного динамического синтеза, анализа и консолидации больших объемов многомерных данных. Существует так называемый <тест FASMI>, содержащий основные принципы OLAP-технологий:
- Fast (быстрый) - предоставление результатов анализа за приемлемое время (обычно не более пяти секунд);
- Analysis (анализ) - возможность проведения любого логического и статистического анализа данных, а также сохранения его результатов в доступном для пользователя виде;
- Shared (разделяемый) - многопользовательский доступ к данным с поддержкой механизмов блокировок и авторизованного доступа;
- Multidimensional (многомерный) - многомерное представление данных на концептуальном уровне, включая полную поддержку иерархий и множественных иерархий;
- Information (информации) - возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
Для того чтобы удовлетворить требования относительно времени анализа данных и получения ответа на сложные запросы, понадобилось задействовать новую технологию организации и хранения данных. Эта новая технология получила название <хранилище данных> (Data Warehouse).
Хранилище данных. Согласно определению автора концепции хранилища данных Б. Инмона [6.8]), это <предметно-ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные для целей поддержки принятия решений>. В этом определении под интеграцией данных понимается объединение и согласованное представление данных из различных источников. <Поддержка хронологии> означает наличие <исторических> данных, т.е. данных, соответствующих интервалу времени, предшествующему текущему моменту. <Неизменчивость данных> означает, что изменение данных в хранилище осуществляется путем добавления новых данных, соответствующих определенному временному интервалу, без изменения информации, уже находящейся в хранилище.
К основным требованиям, предъявляемым к хранилищам данных, относятся:
- поддержка высокой скорости получения данных из хранилища (т.е. малого времени реакции на запросы);
- поддержка внутренней непротиворечивости данных;
- возможность получения срезов данных (например, значений совокупности показателей за определенный период, значение одного показателя за ряд последовательных временных интервалов и т.д.);
- наличие удобных средств для просмотра данных в хранилище;
- полнота и достоверность хранимых данных.
Хранилище данных - это единый источник данных, относящихся к функционированию отрасли, предприятия, организации, содержащий всю необходимую и достоверную информацию для поддержки принятия решений.
Типичное хранилище, как правило, отличается от обычной реляционной базы данных. Поясним это утверждение путем рассмотрения логических моделей реляционной базы данных и данных хранилища.
В традиционных базах данных реляционного типа логическая модель данных - это совокупность двумерных (плоских) таблиц, построенных так, чтобы обеспечить возможность наиболее эффективного выполнения различных операций с данными.
Надо отметить, что измерения многомерного куба могут иметь иерархическую структуру. Например, измерение <пункт отправки> может быть представлено трехуровневой иерархической схемой (см. рис. 6.16.).
В отличие от нормализованной логической модели базы данных реляционного типа, логическая модель типа куба допускает избыточность данных, т.е. содержит помимо исходных данных и некоторые заранее вычисленные итоговые данные (агрегированные данные). Это оправдано в СППР, т.к. позволяет уменьшить время реакции системы на сложные запросы.
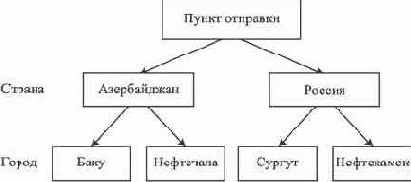
Рис. 6.16. Иерархическая схема измерения "пункт отправки"
Мы рассмотрели логическую модель хранилища, представляющую данные в виде совокупности многомерных кубов. Физическая реализация хранилища обычно осуществляется одним из следующих способов [6.8]:
- с использованием специализированных многомерных структур, отличающихся от традиционных реляционных баз данных;
- с использованием для хранения данных реляционных баз данных;
- гибридное решение: детальные данные хранятся в базах реляционного типа, а агрегированные - в специальных многомерных структурах.
В IBM DB2 OLAP Server поддерживается многомерная модель данных на основе реляционной СУБД DB2 UDB. Средства повышения производительности (см. раздел 6.3.2) позволяют обеспечить требуемые временные характеристики.
Инструменты для создания хранилищ данных позволяют собирать данные из систем управления предприятием и внешних источников, <очищать> их, преобразовывать и загружать в хранилище данных.
На этапе проектирования в распоряжение пользователя предоставляется набор управляемых инструментов для создания хранилищ данных. В его состав входят инструменты, которые позволяют генерировать различные схемы очистки и загрузки данных, а также графически описывать действия, необходимые для построения и сопровождения хранилища данных. Основной программный продукт этой группы - IBM DB2 Warehouse Manager; его назначение, функции и особенности приведены в таблице 6.3.
Средства поддержки доступа к данным представляют собой API и серверы промежуточного ПО, которые поддерживают доступ клиентских инструментов к бизнес-информации, а также обработку этой информации. Связующие программные серверы позволяют клиентам получать прозрачный доступ к многочисленным серверам баз данных (созданным как IBM, так и другими разработчиками). Основные программные продукты этой группы описаны в таблице 6.3.
Средства интеллектуальной обработки данных (<добычи информации>, Intelligent Miner). Основное назначение интеллектуальной обработки данных (ИАД) - поиск в данных скрытых закономерностей. Большинство методов ИАД первоначально разрабатывалось в рамках направления исследований, которое получило название <системы искусственного интеллекта>. Только сейчас, когда образовались большие и быстро растущие массивы корпоративных данных, эти методы оказались в полной мере востребованными.
Сфера поиска закономерностей отличается от оперативной аналитической обработки данных (OLAP) тем, что накопленные сведения в ней автоматически обобщаются до информации, которая может быть охарактеризована как знания. Этот процесс чрезвычайно актуален сейчас, и важность его будет со временем только расти. Как утверждают специалисты, количество информации в мире удваивается каждые 20 месяцев, в то время как компьютерные технологии, обещавшие фонтан мудрости, пока что только регулируют потоки данных.
Интеллектуальный анализ данных определяется в большинстве публикаций как извлечение <зерен знаний из гор данных>. При этом в английском языке существует два термина, переводимые как ИАД, - Knowledge Discovery in Databases (KDD) и Data Mining (DM). В большинстве работ они используются как синонимы.
Покажем на примерах различие задач <оперативной аналитической обработки данных> (OLAP) и <интеллектуального анализа данных> (ИАД). Если задачей OLAP является, например, ответ на вопрос <как изменились эксплуатационные затраты путевого хозяйства Московской железной дороги в период с 1998 по 2002 год?>, то цель ИАД - ответить на вопросы: <какие факторы в наибольшей степени влияют на эксплуатационные расходы путевого хозяйства Московской железной дороги?>, <каковы ожидаемые величины эксплуатационных расходов в 2003 году?> и т.д.
Подобно ассоциациям, последовательности определяют связь между событиями, но наступающими не одновременно, а с некоторым разрывом во времени. Мерой взаимосвязи между последовательными событиями А, В, С могут быть условные вероятности события В при условии, что событие А произошло, и условная вероятность события С при условии, что А и В имели место.
DB2 Intelligent Miner - это набор продуктов, который предоставляет в распоряжение пользователя аналитические инструменты, необходимые для принятия продуманных и качественных бизнес-решений. Задачи, решаемые этим набором продуктов, могут привести к выбору более точной маркетинговой стратегии, к уменьшению оттока заказчиков, к увеличению прибыли от торговли через Internet. Основные продукты семейства DB2 Intelligent Miner описаны в таблице 6.3.
Нормализованная логическая модель базы данных реляционного типа характеризуется, в частности, следующими особенностями:
- все значения, хранимые в ячейках таблиц (значения атрибутов), атомарны (т.е. в каждой ячейке таблицы располагается только одно значение);
- данные не дублируются (т.е. в базе данных отсутствует избыточность).
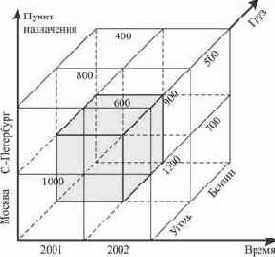
Рис. 6.14. Пример куба, содержащего данные об объемах перевозок грузов
Такое представление данных не всегда соответствует целям поддержки принятия решений, когда возникает необходимость быстрого получения ответов на сложные аналитические запросы. Более адекватной здесь является логическая модель данных в виде многомерного куба [6.8]. Куб - это геометрическая фигура с тремя измерениями. Кубы данных на практике имеют от 4 до 12 измерений; в этих случаях их называют гиперкубами. Измерение в кубе - это одна из характеристик данных. Например, в кубе, показанном на рис. 6.14, измерениями являются <время> (2001 г., 2002 г.), <пункт назначения> (Москва, Санкт-Петербург), <груз> (бензин, уголь). В ячейках куба (рис. 6.14) хранятся данные об объемах перевозок. Эти данные агрегированы по другим измерениям. Например, для куба на рис.6.14, если существует измерение <пункт отправки>, то приведенные на рисунке данные следует рассматривать как агрегированные по этому измерению (т.е. <1000> это есть общая масса угля, завезенного в Москву в 2001 году от всех поставщиков). На многомерном кубе легко определить множество операций, типичных при аналитической работе: сокращение числа измерений (проекции), слияние (объединение кубов, имеющих общие измерения) и т.д. Например, при агрегировании по измерению <груз> куб на рис. 6.14 превращается в квадрат, показанный на рис. 6.15.
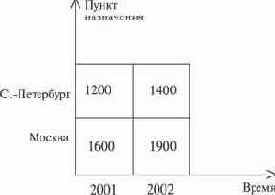
Рис. 6.15. Агрегирование куба рис. 6.3.4 по измерению "груз"
Логическая модель хранилища при этом представляется множеством многомерных кубов (гиперкубов), в общем случае, с различными размерностями, каждый из которых соответствует одному или нескольким количественным показателям отрасли, организации, предприятия.
| 1. | Анализ данных в реальном масштабе времени (OLAP) | IBM DB2 OLAP Server |
|
| 2. | Создание хранилищ данных (Data Warehouse) | IBM DB2 Warehouse Manager |
|
| 3. | Поддержка доступа к данным | Query Management Facility (QMF) |
|
| DB2 Warehouse Manager Connector for SAP R/3 |
| ||
| D2 Warehouse Manager Connector to the Web |
| ||
| DB2 Warehouse Manager Sourcing Agent for z/OS |
| ||
| 4. | Интеллектуальная обработка данных (Intelligence Miner) | DB2 Intelligent Miner Modeling |
|
| DB2 Intelligent Miner Visualizer |
| ||
| DB2 Intelligent Miner Scoring |
| ||
| DB2 Intelligent Miner for Text |
|
Первоначально средства ИАД разрабатывались так, что в качестве исходного материала для анализа принимались данные, организованные в плоские реляционные таблицы. Применение ИАД к данным, представленным с помощью хранилищ в виде гиперкуба, во многих случаях может оказаться более эффективным.
Обычно выделяют следующие пять типов задач ИАД [6.9]:
- Классификация. Наиболее распространенная задача ИАД. Она позволяет выявить признаки, характеризующие однотипные группы объектов - классы, для того, чтобы по известным значениям этих признаков можно было отнести новый объект к тому или иному классу. Ключевым моментом решения этой задачи является анализ множества заранее классифицированных объектов. Наиболее типичный пример использования классификации - конкурентная борьба между поставщиками товаров и услуг за определенные группы клиентов. Классификация может помочь определить характеристики неустойчивых клиентов, склонных перейти к другому поставщику, что позволяет найти оптимальный способ удержать их от этого шага (например, посредством предоставления скидок, льгот или даже с помощью индивидуальной работы с представителями <групп риска>).
- Кластеризация. Логически продолжает идею классификации на более сложный случай, когда сами классы не предопределены, т.е. неизвестна принадлежность заданных объектов тому или иному классу. Результатом использования метода, выполняющего кластеризацию, как раз является вариант разбиения множества объектов на группы, включающие <близкие> объекты. Так, можно выделить родственные группы клиентов или покупателей с тем, чтобы вести в их отношении дифференцированную политику. В приведенном выше примере <группа риска> - категории клиентов, готовых уйти к другому поставщику - средствами кластеризации может быть выявлена до начала процесса ухода, что позволит принимать профилактические, а не экстренные меры.
- Выявление ассоциаций. Ассоциация - это связь между двумя или несколькими одновременно наступающими событиями. Количественной мерой ассоциации может быть, например, условная вероятность события А при условии, что событие В произошло.
- Выявление последовательностей.
Содержание раздела
